[MS] Unlocking Vector Search with OneLake Indexer and OpenAI Integration in Microsoft Fabric - devamazonaws.blogspot.com
Our team works with customer solutions that integrate AI into data solutions. Some time ago, this post titled Fabric Change the Game: Unleashing the Power of Microsoft Fabric and OpenAI for Dataset Search | Microsoft Fabric Blog | Microsoft Fabric was shared in our Fabric Blog community. It explored how to integrate OpenAI capabilities into Microsoft Fabric and was based on insights from our team’s experience. At that time, Microsoft Fabric didn’t offer a built-in OneLake Files indexer. Now that it does, we revisited the topic to evaluate how these new capabilities streamline dataset discovery and enhance AI integration, drawing from our continued work with customers. In this step-by-step guide, we'll dive into vector search using the OneLake Files indexer. You'll learn how to extract searchable content and metadata from your files to power advanced search experiences. We'll also explore how Microsoft Fabric and OpenAI work together, making it easier to build AI-driven solutions within your existing data ecosystem. This approach is especially important today, as many organizations are working to unify their data and AI strategies. To explore this option in Fabric, you will need:
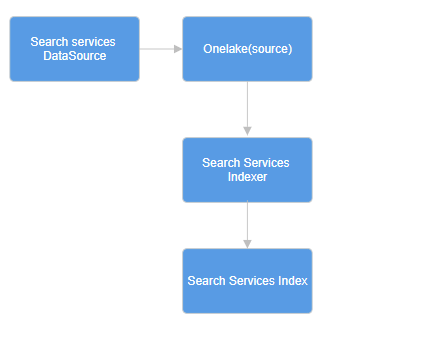 Fig 1 - Flow
Fig 1 - Flow
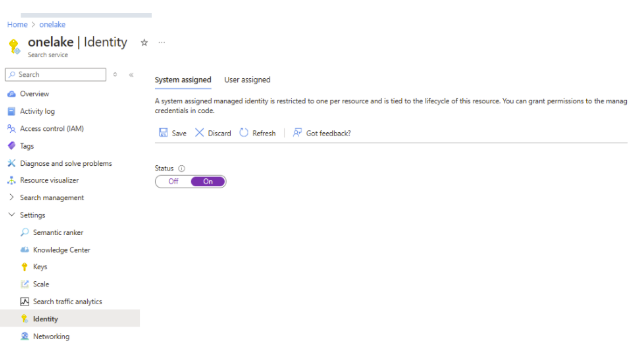 Fig 2 - Identity
Fig 2 - Identity 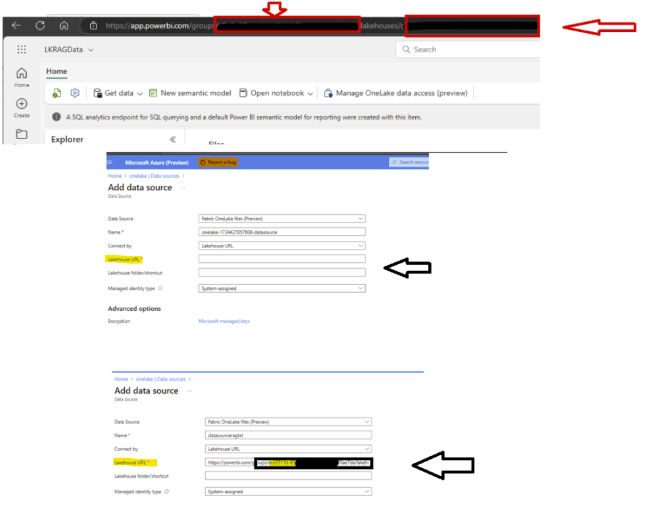 Fig 3 - DataSource
Fig 3 - DataSource
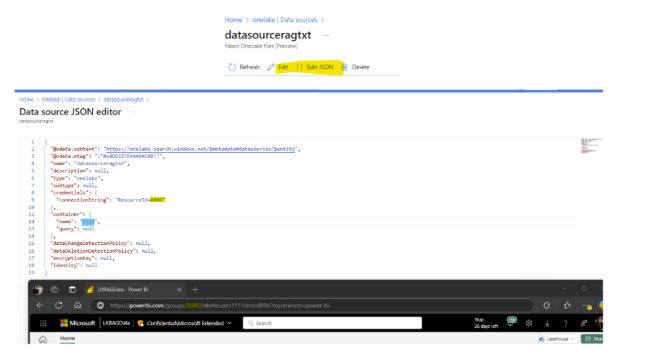 Fig 4 - Json
Fig 4 - Json
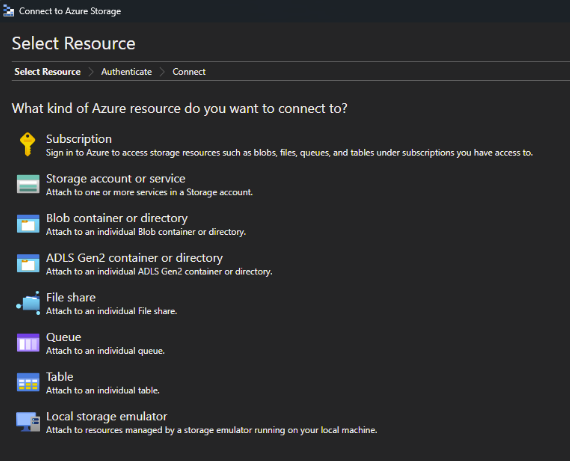 Fig 5 - AzureStorage
Fig 5 - AzureStorage
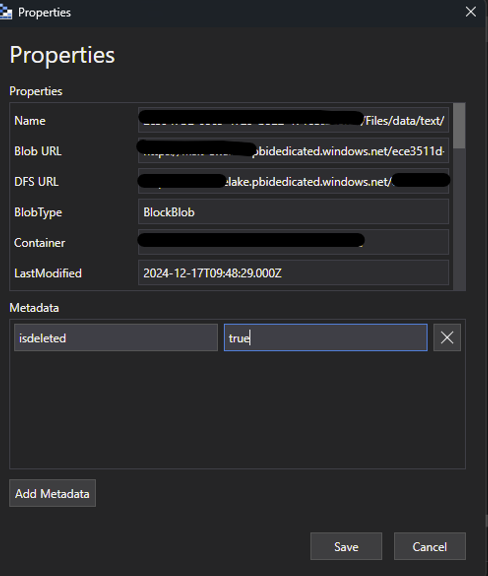 Fig 6 - Properties
Fig 6 - Properties
 Fig 7 - Fabric
Fig 7 - Fabric
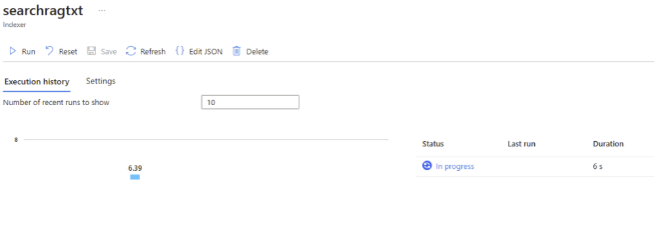 Fig 8 - Run Using the index with the Python script is straightforward. In Fabric, you can open a notebook, connect to the search service, and perform a simple search. Keep in mind, this is just a proof of concept and is not intended for production use. Note: the Search Service Key can be obtained from Search Service -> Settings ->Key. Simple Example:
Fig 8 - Run Using the index with the Python script is straightforward. In Fabric, you can open a notebook, connect to the search service, and perform a simple search. Keep in mind, this is just a proof of concept and is not intended for production use. Note: the Search Service Key can be obtained from Search Service -> Settings ->Key. Simple Example:
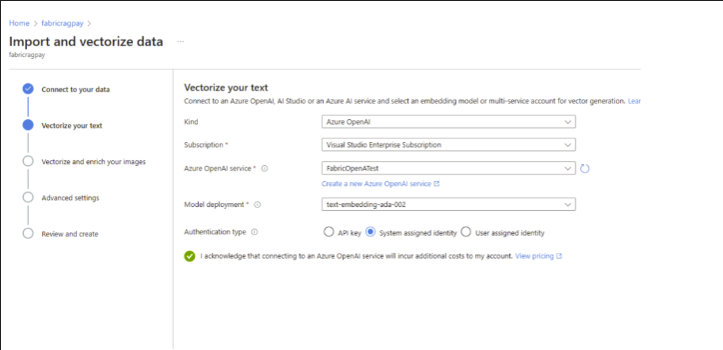 Fig 9 - Vectorize More information about OpenAI: What is Azure OpenAI Service? – Azure AI services | Microsoft Learn Azure OpenAI Service embeddings tutorial – Azure OpenAI | Microsoft Learn From Fabric, you can open a notebook, connect to the search service, and perform the search.
Fig 9 - Vectorize More information about OpenAI: What is Azure OpenAI Service? – Azure AI services | Microsoft Learn Azure OpenAI Service embeddings tutorial – Azure OpenAI | Microsoft Learn From Fabric, you can open a notebook, connect to the search service, and perform the search.
Post Updated on September 03, 2025 at 08:00AM
Thanks for reading
from devamazonaws.blogspot.com
- 2024-05-01-preview REST API or a newer preview REST API.
- Import and vectorize data wizard in the Azure portal.
- A Fabric workspace.
- A Lakehouse in a Fabric workspace.
- Textual data.
- Upload into a lakehouse directly
Step-by Step:
Search Services
This is where things get interesting. The OneLake indexer allows us to create an index on top of the data in OneLake. If you already have the data you want to index, you can proceed. If not, you can use sample data from this repo: Azure-OpenAI-Docs-Samples/Samples/Tutorials/Embeddings/embedding_billsum.ipynb. But what is an indexer? Basically, an indexer in Azure AI Search is a tool that crawls cloud data sources, extracts textual data, and populates a search index by mapping fields between the source data and the index. Indexer overview - Azure AI Search | Microsoft Learn. An indexer targets a supported data source, with its configuration specifying both the data source (such as OneLake) and the search index (destination). It is recommended to create a separate indexer for each combination of target index and data source. Multiple indexers can write to the same index, and a single data source can be reused across multiple indexers, as shown in Fig 1 - Flow. Fig 1 - Flow
Search Services configuration:
- If you haven't already, upload your data to OneLake inside the Lakehouse (Options to get data into the Lakehouse - Microsoft Fabric | Microsoft Learn).
- Deploy the Search Services (Create a search service in the Azure portal - Azure AI Search | Microsoft Learn)
- Enable identity in the Search Services as Fig 2 - Identity
Fig 2 - Identity Fig 3 - DataSource
- Once you create the data source, you can open the JSON editor (as shown in Fig 4 - Json). You will see that the ResourceID contains the Fabric Workspace GUID, and the Container points to the Lakehouse GUID.
Fig 4 - Json
- The documentation mentions that it is possible to detect when a document is flagged for deletion. To configure this, connect to Azure Storage Explorer as shown in Fig 5 - AzureStorage. Integrate OneLake with Azure Storage Explorer - Microsoft Fabric | Microsoft Learn.
Fig 5 - AzureStorage
- Connect to the subscription and choose ADLS
- Add the metadata configuration as shown in Figure 6 – Properties in Azure Storage Explorer.
Fig 6 - Properties
- In Azure AI Search, edit the data source Json definition to include a "dataDeletionDetectionPolicy" property.
{
"@odata.context": "https://onelake.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0xXX\"",
"name": "define a name",
"description": null,
"type": "onelake",
"subtype": null,
"credentials": {
"connectionString": "ResourceId=1111"
},
"container": {
"name": "0000",
"query": "data"
},
"dataDeletionDetectionPolicy": {
"@odata.type": "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy",
"softDeleteColumnName": "isdeleted",
"softDeleteMarkerValue": "true"
},
"dataChangeDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}- Create the index and indexer that are relevant for the filter you are creating. Here is the documentation example:OneLake indexer (preview) - Azure AI Search | Microsoft Learn
{
"name" : "Define A name",
"fields": [
{ "name": "ID", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false },
{ "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true },
{ "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true },
{ "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }
]
}{
"name": "searchragtxt",
"dataSourceName": "name of your datasource",
"targetIndexName": "name of your index",
"fieldMappings": [
{
"sourceFieldName": "content",
"targetFieldName": "content"
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
},
{
"sourceFieldName": "metadata_storage_size",
"targetFieldName": "metadata_storage_size"
},
{
"sourceFieldName": "metadata_storage_content_type",
"targetFieldName": "metadata_storage_content_type"
}
],
"parameters": {
"configuration": {
"dataToExtract": "contentAndMetadata",
"delimitedTextHeaders": "true",
"delimitedTextDelimiter": ","
}
}
}- Run the indexer, as shown in Fig 8 - Run:
Fig 8 - Run Using the index with the Python script is straightforward. In Fabric, you can open a notebook, connect to the search service, and perform a simple search. Keep in mind, this is just a proof of concept and is not intended for production use. Note: the Search Service Key can be obtained from Search Service -> Settings ->Key. Simple Example:
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
SearchIndex, SimpleField, SearchFieldDataType, SearchableField
)
from azure.search.documents.indexes import SearchIndexClient
from azure.core.credentials import AzureKeyCredential
service_endpoint = "https://NAMEOFTHESEARCHSERVICE.search.windows.net"
api_key = "APIKEY"
index_name = "NAME OF THE INDEX"
search_client = SearchClient(endpoint=service_endpoint, index_name=index_name, credential=AzureKeyCredential(api_key))
query = "Any relevant question for the content uploaded?"
results = search_client.search(search_text=query, top=3)
retrieved_docs = []
for result in results:
retrieved_docs.append(result['content'])
print("Retrieved content:")
for doc in retrieved_docs:
print(doc)Vectorize
Another option is to use the wizard, which eliminates the need for coding to build an index. This enables you to craft engaging queries in just minutes. It automatically generates multiple objects on your search service: a searchable index, an indexer, and a data source connection for seamless data retrieval. More information Configure a vectorizer - Azure AI Search | Microsoft Learn You can do this by following the steps in the documentation: Quickstart: Vector Search in the Azure Portal - Azure AI Search | Microsoft Learn. From there, connect the data source to OneLake in just a few clicks. Note: Deploying an OpenAI service is required, as mentioned in the documentation. The user performing the deployment must have the Cognitive Services Contributor permission. You'll also need to define a deployment model, as shown in Fig 9 - Vectorize. An option istext-embedding-ada-002, which is an OpenAI model designed to convert text into numerical vector representations, making it useful for tasks like semantic search, recommendation systems, and clustering. For example, consider these scenarios:
- Semantic Search: Instead of relying on keyword matching, searches return results based on meaning.
- Recommendation Systems: Similarity between text embeddings helps suggest relevant content.
- Clustering & Categorization: Text with similar meanings gets grouped together.
Fig 9 - Vectorize More information about OpenAI: What is Azure OpenAI Service? – Azure AI services | Microsoft Learn Azure OpenAI Service embeddings tutorial – Azure OpenAI | Microsoft Learn From Fabric, you can open a notebook, connect to the search service, and perform the search.
from azure.search.documents import SearchClient
from azure.search.documents.models import VectorizableTextQuery
from azure.identity import DefaultAzureCredential
from azure.core.credentials import AzureKeyCredential
# Pure Vector Search
query = "can you fill with a relevant question ?"
credential = AzureKeyCredential("Search Services KEY")
endpoint = "https://nameoftheSearchservicecreated.search.windows.net"
index_name = "name of the index created"
search_client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
vector_query = VectorizableTextQuery(text=query, k_nearest_neighbors=1, fields="text_vector", exhaustive=True)
results = search_client.search(
search_text=query,
vector_queries= [vector_query],
top=1
)
for result in results:
print(f"title: {result['title']}")
print(f"Score: {result['@search.score']}")
print(f"chunk: {result['chunk']}")OpenAI and Microsoft Fabric Seamless integration
Another option is to use Fabric and OpenAI. Fabric seamlessly integrates with Azure AI services, enabling you to enhance your data with prebuilt AI models without any prior setup. Use Azure AI services in Fabric - Microsoft Fabric | Microsoft Learn This is the easiest way to use OpenAI and Microsoft Fabric: simply import the library, choose a supported model, and start using it. Use Azure OpenAI with Python SDK - Microsoft Fabric | Microsoft LearnSummary
In this post, we explored how to leverage OneLake's indexer for vector search to extract searchable data and metadata. We also discussed the seamless integration of Microsoft Fabric with OpenAI, showing how these tools work together for efficient data processing and AI-driven insights.Post Updated on September 03, 2025 at 08:00AM
Thanks for reading
from devamazonaws.blogspot.com
Comments
Post a Comment