[MS] From Azure IoT Operations Data Processor Pipelines to Dataflows - devamazonaws.blogspot.com
We recently completed an 18-month journey building an event detection system at the edge with Azure IoT Operations (AIO). The goal was simple to describe but complex to execute: use a Vision Model to detect real-world events, then raise confidence by correlating that signal with other data sources—from industrial sensors to weather APIs. This meant designing heuristic logic at the edge: the “brain” that fuses data from multiple inputs to decide if something really happened. And as the technology evolved, so did our architecture.
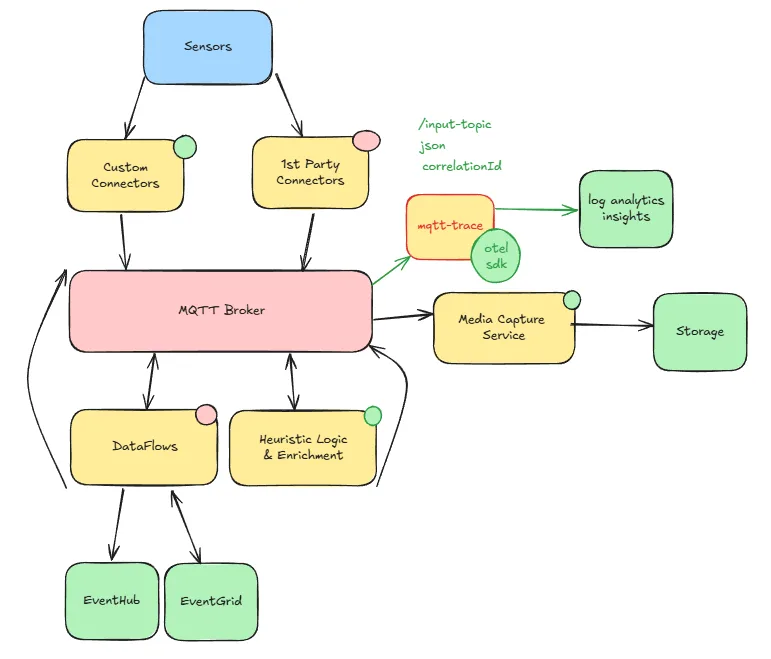 Figure: High-level architecture—Rust pods handle heavy processing, Dataflows manage lightweight tasks, all coordinated via MQTT broker. That decision paid off:
Figure: High-level architecture—Rust pods handle heavy processing, Dataflows manage lightweight tasks, all coordinated via MQTT broker. That decision paid off:
Post Updated on March 19, 2026 at 07:00AM
Thanks for reading
from devamazonaws.blogspot.com
The Evolution: From jq Pipelines to WASM Dataflows
When we started, we leaned on AIO Data Processor Pipelines—a familiar tool we had used before for Overall Equipment Effectiveness (OEE) calculations. It was simple, declarative, and built onjq (JSON Query), making transformations approachable. We even published a blog post in July 2024 about how effective it was. But when we took our processing logic to a pilot in production, the Azure IoT Operations team introduced the Dataflow component, which evolved from the original Pipelines. This change was shaped by customer and partner feedback—including ours. Dataflow brought both excitement and new challenges:
- Exciting because it provided a richer, more robust framework for connecting multiple data sources.
- Challenging because it required us to rethink our architecture and adjust existing pipelines.
- Expression-based Dataflows: out-of-the-box functions with a rich expression language.
- WASM-based Dataflows: full flexibility to embed custom, managed code inside the flow.
Hybrid Approach: Rust Pods + Dataflows
Instead of using a rip-and-replace approach, we chose a hybrid approach:- Custom Rust Pods handled heavy transformations, enrichment, and heuristic logic.
- Dataflows managed lightweight tasks: routing, filtering, simple enrichment, and connectivity (e.g., syncing to Azure Event Grid).
A Deep Dive Into Our Transformations
Over time, we built a small Rust transformation library that became our toolkit. Some highlights:1. Enrichment: Adding Context
We appended environment variables, cluster metadata, or system data to incoming messages. This gave downstream systems richer context without extra lookups.2. Last Known Value (LKV): Handling Gaps
Sensors are chatty—until they aren’t. Inspired by Pipelines, we built an LKV trait with two implementations:- In-memory cache for dev/test.
- MQTT-backed store for production.
3. Mapping & Standardization
Different devices spoke different “dialects.” We normalized units, standardized names, and translated site codes. This reduced integration headaches. Pro tip: keep mapping logic separate from heuristic logic—simpler to debug, swap, and test.4. Filtering: Reducing Noise
From basic field checks to nested conditions, filtering kept pipelines focused on what mattered. We even used hierarchical MQTT topics to reflect filtering stages, making it easy to trace message paths.5. Heuristic & Arithmetic Logic
This was the “secret sauce.” We combined arithmetic, heuristics, and lightweight ML anomaly detection—reusable via a shared Rust crate. Once the building blocks were in place, the “hardest” part became the simplest.Scaling the Architecture
Each transformation ran as an independent Rust thread, grouped into pods. This gave us fine-grained scalability:- Scale high-volume enrichment pods separately from compute-heavy heuristics.
- Deploy on Kubernetes with node affinity and replica tuning.
- Isolate failures—one broken stage didn’t topple the system.
MQTT as the Brain
From day one, MQTT was our nervous system. Every component—Rust pod, Dataflow, sensor, or cloud connector—spoke through the broker. We didn’t wire services together directly; we published and subscribed to topics. Figure: High-level architecture—Rust pods handle heavy processing, Dataflows manage lightweight tasks, all coordinated via MQTT broker. That decision paid off:
- Decoupling: Each component only needed to know its topic. We could add, remove, or rewire logic without breaking others.
- Tracing: Because everything flowed through MQTT, we built a tracing component that correlated events across the system. It was as simple as subscribing to multiple topics and reconstructing event lifecycles.
- Scalability: By partitioning topics, we scaled horizontally. We could route high-volume data to one broker, critical alerts to another, or separate ingestion (frontends) from processing (backends).
- Flexibility: MQTT let us experiment—run multiple versions of a component in parallel, replay messages from retained topics, or test new heuristics without touching production wiring.
Lessons Learned
Eighteen months, several rewrites, and one major platform evolution later, here’s what we’d tell our past selves:- Modularity Wins: Whether in jq, Rust, or Dataflows, keep logic small and composable. Easier to debug, scale, and migrate.
- Hybrid Is Practical: Don’t chase “all-in” rewrites. Dataflows for routing; Rust (or the language of your choice) for heavy lifting.
- Context Is Everything: Enrichment and LKV strategies are essential for meaningful, resilient data.
- MQTT Is the Brain: Treat the broker as the system’s nervous system. Route everything through it, and you unlock tracing, scalability, and decoupling.
The Takeaway: Design for Change
Edge AI and IoT environments evolve rapidly. Components shift, features are redefined, and what works today may no longer be viable tomorrow. The most effective way to stay resilient is to design for modularity, flexibility, and hybrid operation from the start. Keeping components lightweight and single-purpose not only improves performance but also simplifies troubleshooting. When each stage does one thing well, it is easier to isolate failures, replace or upgrade logic, and trace problems end-to-end. This modularity accelerates debugging and enables faster iteration as requirements or technologies change. For teams working in this space, we recommend following Microsoft’s Edge AI Accelerator. It provides patterns, tools, and guidance for building scalable and production-ready edge AI solutions, many of which align with the lessons we share here. Whether you are building event detection systems at the edge, adopting AIO Dataflows, or experimenting with custom heuristics, the core guidance remains the same: keep your architecture modular and flexible, and let MQTT serve as the central nervous system that—when sized, partitioned, and tuned correctly—can enable scaling, tracing, and long-term evolution.Post Updated on March 19, 2026 at 07:00AM
Thanks for reading
from devamazonaws.blogspot.com
Comments
Post a Comment