[MS] SQL query generation from natural language - devamazonaws.blogspot.com
Introduction
Converting natural language questions to SQL is valuable but difficult. At first glance, given a question and a database schema, generating correct SQL seems straightforward. In reality, it is complex. LLMs must understand table relationships, disambiguate terminology, apply correct joins, and handle real-world database messiness: obscure table and column names, unnormalized data, and key data buried in JSON columns. To face these challenges, you need a system capable of performing interactive data discovery and reasoning over intermediate results. This system must then create a SQL query that retrieves the data needed to satisfy the user's question. This post describes our approach to building a system which translates natural language (NL) user questions to SQL queries. We evaluated multiple AI agent approaches (Azure Databricks AI/BI Genie, custom implementations via GitHub Copilot CLI and Microsoft Agent Framework) using an evaluation framework derived from LiveSQLBench to measure progress. After performing various experiments, we achieved an accuracy of approximately 75% with our custom implementations. In this post, we share practical insights and lessons for building similar systems. Given the database messiness described above, our research focused specifically on exploring unknown or poorly documented databases—a scenario where simple schema-based approaches fail and adaptive reasoning becomes essential. This contrasts with the well-studied case of well-annotated schemas, where existing NL-to-SQL solutions already perform effectively; our work targets the harder problem where databases are unfamiliar and metadata is sparse or missing.Research Foundation
Before building anything, we conducted a literature review to gain inspiration from existing approaches. We found the paper RAISE: Reasoning Agent for Interactive SQL Exploration, which describes an agent that answers a user's query prompted in natural language by not only looking at the database schema, but also reasoning more deeply and semantically by exploring the actual data found in the tables. This paper guided our exploration decisions and helped us avoid undesirable behaviors such as answering questions prematurely without sufficiently understanding the available data and getting stuck in unproductive reasoning loops.Dataset
Following the research, we searched for an existing dataset that could demonstrate real-world database complexity. We used the LiveSQLBench dataset, a benchmark designed exactly for the purpose of real-world NL-to-SQL tasks. We focused on medium-complexitySELECT queries (2-3 table joins, multiple WHERE
conditions) on databases with 10+ tables. The queries featured the real-world
messiness we wanted to tackle:
- Obscure table and column names, and unclear or undocumented relationships (for example, missing foreign keys and implicit joins)
- JSON columns storing semi-structured data
- Issues due to denormalized data
- Multiple valid interpretations of ambiguous questions
Approach and Solution
We tested three different approaches, progressing from rapid prototyping to using production-grade frameworks. This allowed us to study how existing agentic tools performed before building our own custom implementations, while maintaining consistent evaluation criteria. All solutions were evaluated against a common benchmark described below. We progressed through the following experiments:- GitHub Copilot CLI: Quick validation of the RAISE approach with access to multiple model providers
- Microsoft Agent Framework: Refined implementation using Microsoft's main agent framework
- AI/BI Genie: Baseline comparison against AI/BI Genie, a feature of Azure Databricks that lets business users ask questions about their data in natural language
Logical Flow
The diagram below shows a simplified agentic flow that the three solutions followed.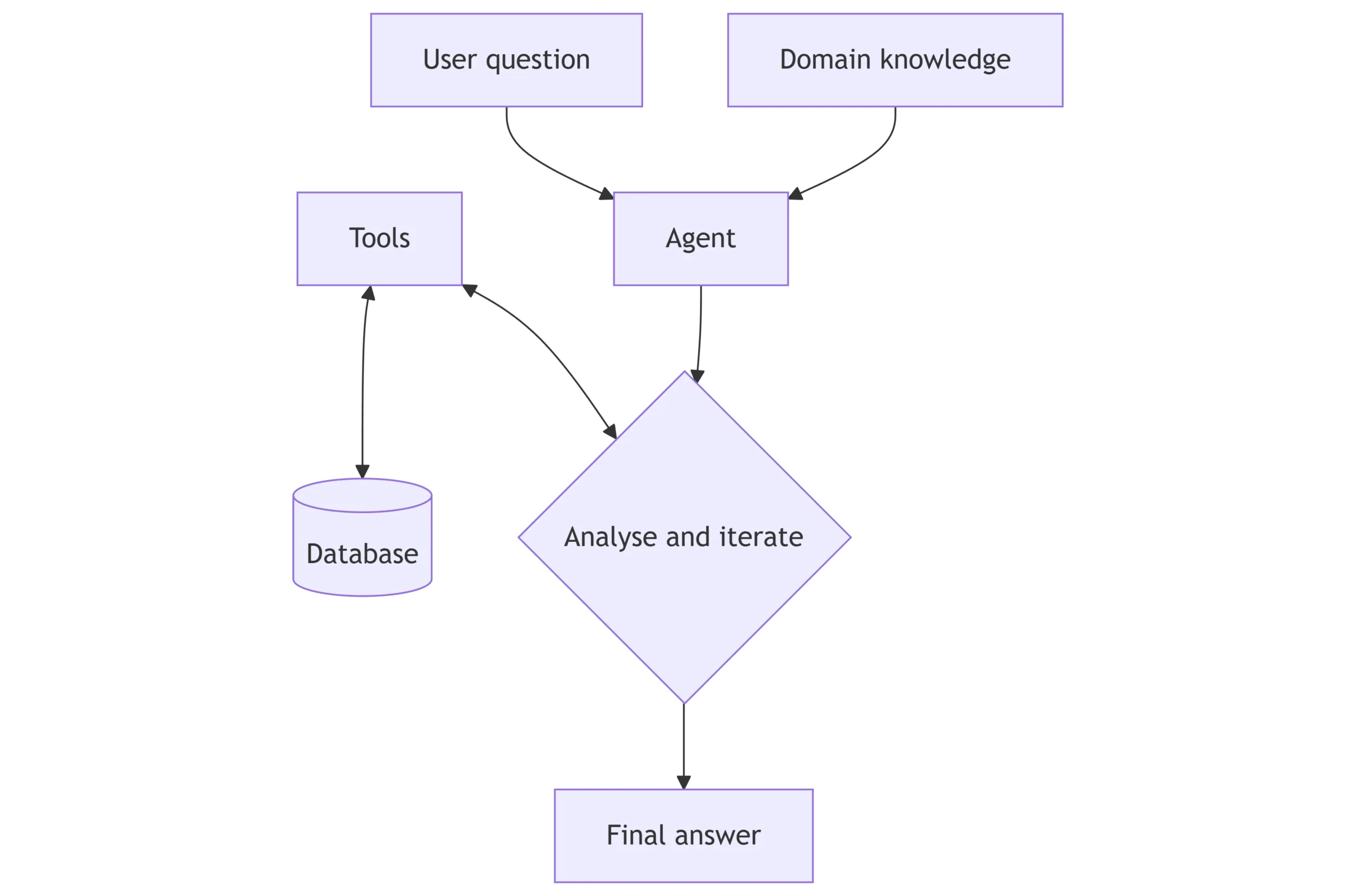
GitHub Copilot CLI
We built an initial proof of concept following RAISE paper principles to validate if a single agent with appropriate tooling could successfully generate the expected SQL queries. This approach enabled us to explore LLM models (like Gemini 3.0 and Claude Sonnet 4.5) not yet available on Microsoft Foundry at time of writing. The agent had access to four core tools:get_db_schema(): Returns schema for all tables (column names, data types, constraints, foreign keys)get_tb_table_schema(name): Returns detailed schema for a specific table (columns, types, constraints, foreign keys)get_db_table_list(): Lists all table namesquery_db(sql): Executes SQL query and returns the resulting data
Microsoft Agent Framework
We developed a custom implementation expanding on what we learned with the GitHub Copilot CLI, using the same tool set but within Microsoft Foundry. We kept the design intentionally simple by using a straightforward agentic loop rather than orchestrating sub-agents and other advanced features of the framework. We found this granularity was sufficient for strong performance.Azure Databricks AI/BI Genie
We evaluated AI/BI Genie, an existing enterprise solution from Azure Databricks' ecosystem that lets users interact with data using natural language, leveraging generative AI and Unity Catalog metadata. We conducted a series of experiments to understand how metadata enrichment affects accuracy in production tools. We progressed through multiple configurations: starting with empty Genie Spaces, then adding column descriptions, populating the Knowledge Store with domain specific instructions, and finally using Genie's feedback mechanism to iteratively save and reuse correct SQL patterns. See AI/BI Genie documentation for more details. Genie performed poorly when little or no metadata/annotations were available, but became strong once we added column descriptions and domain instructions. Because curating detailed metadata was not the focus of our investigation, we stopped the Genie track after capturing these results.Evaluation Methodology
We needed to track performance consistently across solutions, so we standardized the evaluation process and metrics used by every experiment run.Evaluation
For each query in the dataset, we performed the following:- Generated Ground Truth: Executed the canonical SQL query against the database and captured the exact results.
- Prompted the agent: Each system under test received only the natural language question.
- Captured interim agent responses and function calls: Logged every message and tool invocation to enable step-by-step tracing, error diagnosis, and metric attribution.
- Captured the Prediction: The agent generated a SQL query and we executed it to get the results from the prediction.
- Compared Results: We measured success using a flexible matching approach:
- Floating-point tolerance: Numerical values were compared with a configurable tolerance value. This handles floating-point precision issues while keeping results accurate.
- Case-insensitive strings: Text values were compared case-insensitively to handle differences in casing.
- Row-level matching: Bipartite matching ensured each ground truth row uniquely matched a predicted row, correctly handling duplicate values.
Example
1. Question - Which modern-style homes (like brickwork houses or apartments) in the Guará area also have TV service? List their household numbers in order 2. Agent prompt - instructions and hints for domain knowledge (business context like what fields mean, how data relates, and calculation formulas) (snippet below):...Your task is to generate a correct PostgreSQL query to answer the user's [Question]. You may be given a [Hint] that will help you solve the question...
[Hint]:
- Income Classification (value_illustration):
Illustrates the income brackets for household economic status.
Ranges from 'Low Income' to 'Very High Income'. Null indicates undisclosed or irregular income.{"type": "call", "function": "get_db_table_list", "arguments": {}}
{"type": "return", "result": "amenities\nhouseholds\n..."}
{"type": "call", "function": "get_tb_table_schema", "arguments": {"name": "households"}}SELECT DISTINCT households.housenum
FROM households
JOIN properties ON properties.houselink = households.housenum
JOIN amenities ON amenities.houseid = households.housenum
WHERE TRIM(UPPER(households.locregion)) = 'GUARÁ'
AND TRIM(UPPER(properties.dwelling_specs->>'Dwelling_Class')) IN ('BRICKWORK HOUSE','APARTMENT','CONDOMINIUM')
AND TRIM(UPPER(amenities.cablestatus)) IN ('AVAIL','AVAILABLE','YES')
ORDER BY households.housenum;{"housenum": "35"}, {"housenum": "234"}, ...Experiments
We systematically evaluated what factors improve or hinder NL-to-SQL accuracy across three approaches. The experiments revealed clear patterns in system performance and identified both solvable technical challenges and fundamental limitations.Experimental Journey
Our experiments followed an iterative approach focused on understanding how metadata and validation mechanisms improve query generation. We tested each change against our standardized evaluation dataset, allowing us to isolate the impact of individual improvements. The results below show this progression. For clarity in the tables below: Metadata refers to technical schema context (table and column descriptions, types, relationships), and domain hints are business domain instructions we inject into prompts or a knowledge store to explain what fields mean and how metrics should be computed.Experiment Overview
GitHub Copilot CLI
| Model | Experiment Description | Accuracy |
|---|---|---|
| Claude Sonnet 4.5 | Metadata only | 66.70% |
| Claude Sonnet 4.5 | Metadata and domain hints | 80.77% |
| Gemini 3.0 Pro Preview | Metadata and domain hints | 74.07% |
Microsoft Agent Framework
| Model | Experiment Description | Accuracy |
|---|---|---|
| GPT-5 Mini | Metadata only | 55.60% |
| GPT-5 Mini | Metadata and domain hints | 65.38% |
| GPT-5 Mini | Metadata and additional clarification agent tool providing domain knowledge | 69.23% |
| GPT-5 Mini | Metadata and domain hints with revisions to agent instructions | 76.92% |
| GPT-5 Mini | Ablation study - removing ability to query data | 38.46% |
Azure Databricks AI/BI Genie
| Experiment Description | Accuracy |
|---|---|
| Empty Spaces - no metadata or knowledge store | 9.50% |
| Added column descriptions plus system instructions with domain knowledge | 69.23% |
| Feedback mechanism - storing SQL patterns and joins from 3 feedback iterations | 88.50% |
Findings
Schema Knowledge + Live Validation
Field-level metadata (technical schema details like column types and constraints) and documentation (semantic understanding of what fields mean) are both critical to successful query generation. Runtime database access allows the agent to test and validate its SQL before producing the final result. Giving the agent better schema/context lifted accuracy across all systems, and letting it actually run queries to sanity-check its SQL was essential. When we removed runtime querying, accuracy collapsed to 38.46%, so metadata alone was not enough—execution feedback mattered. The gain from having metadata available was substantial: AI/BI Genie improved from 9.50% to 69.23%; Copilot CLI (Claude Sonnet 4.5) improved from 66.70% to 80.77%; and the Agent Framework (GPT-5) improved from 55.60% to 69.23%.Model Selection
Claude Sonnet 4.5 reached 80.77% accuracy vs. GPT-5 Mini at 69.23% on identical datasets, prompts, and evaluation criteria in these final experiments. Our default and baseline model was GPT-5 Mini (we developed prompts there first); Claude generally performed better across many runs and produced more comprehensive answers with the same prompt. This reflects model behavior on this setup, not a universal ranking. Gemini 3.0 Pro Preview scored 74.07% on the same prompt and meta data. It showed strengths in whitespace/temporal normalization and even surpassed ground truth quality in a few cases, but had gaps in join-path coverage and JSON field selection. Models have distinct strengths and weaknesses, making it important to evaluate multiple options based on specific schema characteristics, latency/cost constraints, and error tolerance requirements.Iterative Refinement and Feedback Loops
Beyond initial prompt engineering and metadata setup, iterative feedback mechanisms unlock significant additional improvements. In our AI/BI Genie evaluation, we found that storing corrected SQL patterns and learned joins from user feedback improved accuracy by 19.27 percentage points (69.23% to 88.50%). This progression demonstrates that NL-to-SQL systems benefit from production feedback loops where successful query patterns are captured and reused, particularly for repeated query types and domain-specific patterns. This suggests that production systems should consider mechanisms to identify common queries, validate results, and feed corrections back into the knowledge base for continuous improvement. Genie's feedback loop captures and reuses corrected queries, making it strong for optimizing known or repeated queries, but applying those improvements is largely manual; it lacks automation for end-to-end evaluation or broad data exploration, so it is less suited to hands-free exploration.Business Logic Limitations
The majority of the remaining failures across all systems were business logic errors: queries that executed successfully but returned incorrect results due to semantic misunderstanding. This represents a fundamental challenge distinct from technical SQL generation. Examples include:- Incomplete cost aggregations (5 of 8 required fields, 46.00% underestimation).
- Incorrect metric calculations (recomputing values rather than using pre-calculated columns, which risked misalignment in calculation logic, units, or decimal precision).
- Ambiguous interpretations (pattern matching "ultra-low temperature" vs. specific "-70°C" value).
Evaluation Strategy
While our flexible matching approach handled numeric precision and row-level variations, structural differences remained challenging. Queries returning different numbers of columns, whitespace normalization, and semantic aliases could make functionally equivalent results appear different. Adjusting evaluation for these raised accuracy significantly. In a few cases the prediction outperformed ground truth (e.g., better whitespace normalization and temporal filtering). We learned that evaluation strategy design should occur early in the process and be tuned to the specific domain (e.g., numeric tolerance for finance, column flexibility for messy schemas) to avoid marking correct solutions as failures.False Negative Example
When asked to calculate the percentage of returns with warranty claims, the ground truth returned:{"wcr_percent": "53.30"}{"total_returns": "1500", "returns_with_warranty_claim": "799", "percent_with_warranty_claim": "53.30"}Conclusion
NL-to-SQL generation with AI agents can achieve high success rates with the right approach. Our experiments demonstrate that combining runtime data querying with comprehensive schema information (both technical metadata and domain documentation) is critical—without it, accuracy drops significantly (by 13-79 percentage points depending on the system). Model choice matters substantially: Claude Sonnet 4.5 reached 80.77% vs. GPT-5 Mini at 69.23% on identical tasks. Invest time trialing models to find the right fit for your schema, latency/cost constraints, and error tolerance. However, our work also revealed fundamental limitations, particularly the business logic errors discussed earlier that require dedicated domain expertise to address. Key takeaways for practitioners:- Start with schema documentation and runtime validation - These provide the highest ROI for accuracy improvements
- Design evaluation early - Choose evaluation criteria that align with your data characteristics and business goals. This ensures your experimentation actually measures what matters and reveals genuine improvements.
- Expect business logic iteration - Budget for domain expert review and continuous refinement
- Trial multiple models - Performance differences of 10-20 percentage points are common
Post Updated on May 7, 2026 at 08:00AM
Thanks for reading
from devamazonaws.blogspot.com

Comments
Post a Comment