[MS] Scaling AI for silicon - devamazonaws.blogspot.com
Modern AI systems have transformed software engineering, but their impact in silicon development has been limited. The primary constraint is that silicon engineering depends on assembling and reasoning over context that is distributed across many systems. Specifications, logs, regressions, waveforms, and prior debug history all contribute to understanding a problem, yet they are rarely accessible within a single workflow.
Early applications of AI in this space focused on code generation and isolated tasks. These approaches proved useful for scripting and tooling, but had little effect on core design and verification work. The underlying issue is that most engineering effort is spent reconstructing context before meaningful reasoning can begin. When that context remains fragmented, AI systems operate on partial information and cannot participate in the full problem-solving process.
This reflects a fundamental difference in how progress is made. Software workflows can rely on rapid iteration, where new code can be generated and validated quickly. In silicon development, feedback loops are slower, failures are indirect, and observability is limited. Engineers must build an understanding of the system by tracing behavior across time and correlating multiple sources of data. The ability to navigate and assemble that context determines how quickly problems can be understood and resolved.
We addressed this by embedding AI directly into the engineering workflow so it could operate over the full working context. This led to Silicon AI Lab (SAIL), a system that integrates specifications, logs, design data, and engineering history into a single interaction model. The system began as a focused effort to reduce debug friction, and evolved into a platform that supports end-to-end reasoning across engineering tasks.
Results: schedule impact under real constraints
Across programs, the most consistent effect of SAIL has been to improve the quality of AI assistance in day-to-day engineering work. By making relevant engineering context accessible within the workflow, the system enables models to generate more accurate responses and automate tasks that previously required manual effort.
This effect is continuous but difficult to measure directly. Much of the value comes from improving the quality of model outputs in small, repeated interactions, enabling engineers to automate tasks that would otherwise require manual lookup, correlation, and verification. These improvements accumulate over the course of a program, but they are diffuse and not captured by a single metric.
The impact becomes much more visible under disruption. When teams lose expertise, inherit unfamiliar areas, or accumulate backlog under time pressure, progress depends on how quickly engineers can reconstruct the context behind ongoing work. In these scenarios, improved model outputs and increased automation translate directly into measurable schedule outcomes.
The following scenarios illustrate this pattern under different forms of pressure, using examples from the Ruby Mountain project with sensitive details removed.
Vignette 1: attrition on a small team, slip contained from months to weeks
In one verification team, the program lost a senior engineer during a critical execution window, representing a material portion of a small core team. On prior programs, a comparable loss typically translated to a quarter-scale schedule slip. With SAIL in place, the impact was contained to weeks rather than months, with execution velocity recovering quickly. This outcome reflects how SAIL is used elsewhere: by grounding AI in design context and prior debug history, engineers could generate accurate, actionable outputs that allowed incoming and junior engineers to contribute independently. This reduced reliance on constant knowledge transfer and allowed experienced engineers to stay focused on execution. Reusable workflows increased throughput without increasing headcount. In parallel, AI-driven review workflows automated recurring testplan and checklist reviews, reducing effort by roughly an order of magnitude while improving consistency during a constrained period.
Vignette 2: resource gap and backlog, recovered without schedule impact
In another team, a critical resource gap created a multi-sprint backlog during a late-stage verification push. SAIL helped the team recover the backlog while holding the next major milestone. This follows the same pattern seen in other teams: by grounding AI in specification context, test patterns, and debug history, engineers could generate the outputs needed to understand issues and begin contributing immediately. This reduced the training load on the remaining team and avoided pulling experienced engineers off deliverables to onboard new resources. The net result was backlog recovery without deferring work or degrading verification quality.
Vignette 3: late-stage ownership transfer, slip contained to about a sprint
In a late-stage execution window, a key engineer exited while owning multiple critical-path responsibilities, forcing rapid redistribution of ownership on an already small team. Despite the disruption, schedule impact was contained to about a sprint because engineers were able to generate accurate analyses of failing tests and prior investigations for areas they had not previously owned. This follows the same pattern seen in other teams: by grounding AI in logs, specifications, and prior analysis, SAIL enabled engineers to quickly understand unfamiliar areas and make progress under time pressure without repeating dead ends. Without this, the loss of ownership and debug context would typically have produced a significantly larger slip in a critical execution phase.
What these results have in common
Across these scenarios, SAIL consistently limits the impact of disruption, reducing schedule slips from months to weeks or a single sprint. SAIL changes how work is executed by enabling models to operate on complete engineering context and generate outputs that engineers can act on immediately. This reduces dependence on individual expertise and allows work to continue even when ownership changes or teams are under pressure.
Complexities in silicon development
Silicon engineering presents a fundamentally different environment for AI systems than software development. Many of the approaches that have proven effective in software do not translate directly because the underlying structure of the problem is different. The results described earlier reflect these underlying constraints and how they shape day-to-day engineering work.
Progress in silicon is driven by reconstructing context. Engineers rarely begin with a well-defined problem statement. Instead, they must assemble relevant information from specifications, logs, regressions, waveforms, and prior investigations before meaningful reasoning can begin.
Feedback loops are slow and expensive. Hardware compile and simulation cycles operate on time scales that are orders of magnitude longer than typical software build and test loops. This limits the effectiveness of rapid iteration. At the same time, failures are often indirect and temporally or physically distant from their root cause. A failing test may only reflect a downstream symptom, requiring engineers to trace behavior across time and understand interactions between concurrent components.
Observability is limited. Many issues do not produce explicit failure signals or clear error conditions, and engineers must infer intent from partial or indirect evidence.
Engineering workflows are tightly coupled to specific environments and toolchains. Data and tools are distributed across different systems, and accessing them often requires manual coordination. This creates friction in day-to-day work and limits the usefulness of tools that operate outside of the engineer’s existing workflow.
Taken together, these constraints make context reconstruction the dominant task in silicon engineering. Enabling AI to operate effectively in this environment requires integrating it directly into the workflow so it can access complete engineering context and generate outputs that engineers can act on.
Design and Development Constraints
The constraints described above directly shaped how AI systems needed to be designed and built for silicon workflows. Earlier approaches consistently failed in predictable ways: development cycles were too slow to keep up with real usage, feedback loops were indirect and delayed, and tools required engineers to step outside their existing workflows. In practice, these systems could not connect to the actual work being done.
To be effective, AI systems in this environment had to avoid these failure modes from the outset. They needed to operate within the existing workflow, respond to real usage in near real time, and integrate tightly with the data and tools engineers already rely on.
Design Constraints
These constraints translate directly into a small set of design requirements that shape how the system is built and used.
One context. Engineers operate within tightly coupled environments, and any requirement to move between tools or systems introduces friction that limits adoption. All capabilities had to exist within the same interaction model, inside the existing workflow. This ensured that improvements were experienced as part of normal work, rather than as an external tool that required deliberate usage.
Embed in existing workflows. By embedding functionality into VS Code and GitHub Copilot, the system avoided the need for onboarding, training, or process changes. Engineers could begin using it immediately in the course of their work. Adoption was driven by immediate value in specific tasks, rather than by top-down rollout or organizational mandates.
Intuitive or invisible. To minimize cognitive overhead, the system needed to feel intuitive to use to align with how engineers reason about problems. The focus was not on exposing features, but on enabling outcomes with minimal interaction cost. This allowed engineers to stay in a continuous reasoning flow, which is critical in complex debug and verification scenarios.
Development Model
Equally important were the constraints placed on how the system was built. Development was intentionally limited to a small group of about a dozen engineers to preserve a tight feedback loop and high development velocity. A clear participation contract was established: users committed to staying on the platform and doing their day-to-day work within it, and in return, the builder committed to turning around bug fixes and feature requests in less than 24 hours.
Keeping users fully on the platform was critical. If engineers moved between their normal workflow and the system, feedback became fragmented and delayed. By concentrating usage in a single environment, issues surfaced in real time, gaps became visible, and improvements could be validated immediately. This kept development tightly aligned with actual workflows.
This contract fundamentally changed the development model. There was no backlog or delayed prioritization. All interaction happened through a single Teams channel, where feedback, issues, and ideas surfaced continuously and were acted on immediately. This created a closed-loop system where usage, feedback, and implementation were directly coupled.
The result was a development cadence driven by responsiveness. By keeping users on the platform and maintaining immediate turnaround on changes, the system evolved at the pace of real usage, with each improvement immediately visible to the same group driving the feedback.
Deployment Strategy
Adoption did not rely on formal rollout. It expanded through peer-driven sharing, as engineers already using the system began demonstrating it to others in small, informal settings. These sessions were often led by junior and mid-level engineers rather than leadership, creating a low-pressure environment where questions, skepticism, and limitations could be discussed openly. This aligned with how engineers evaluate new tools: through direct validation from trusted peers rather than top-down direction.
Together, this created a deployment model driven by usage rather than rollout. As new engineers adopted the system through peer validation, they entered an environment where workflows were already in active use and continuously improving. By the time adoption expanded beyond the initial group, the core interaction model had been validated under sustained usage, enabling scale through the user community rather than centralized rollout.
Origin: from debug tool to platform
DebugKG, the predecessor to SAIL, was the first implementation of these constraints. It started with a narrow and practical target: debug friction. Engineers were spending a significant portion of the debug loop gathering and correlating data across specifications, design code, logs, and issue tracking systems rather than analyzing root causes and making progress. The goal was not to build a broad platform, but to eliminate this friction directly.
The initial implementation embedded AI directly into the engineer's existing workflow in VS Code through GitHub Copilot, where most development and debug activity already occurred. All relevant data was brought into a single interaction loop, making logs, specifications, and ADO artifacts accessible within the same environment so AI could participate directly in the debug process as it was happening.
With this integration in place, the earliest capabilities targeted high-friction tasks in the debug loop. Engineers could analyze failures by generating summaries of logs, identifying key conditions, cross-referencing issues against specifications and known bugs, and reasoning across multiple sources within a single interaction. What had previously required a sequence of manual lookups across different systems could now be performed within one continuous workflow. This shift was not just about speed, but about preserving the engineer’s focus and enabling deeper reasoning without interruption.
The impact was immediate. Debug tasks that had traditionally taken hours were reduced to minutes in many cases, not because the underlying problems were simpler, but because the system enabled engineers to generate accurate analyses without manual context gathering. Engineers were able to stay within a single cognitive flow, moving directly from data access to analysis. More importantly, this phase established the first point of tangible value for AI in silicon workflows and built trust among users. The system was no longer seen as an experimental tool, but as a practical capability that improved execution.
Once this value was established, the scope of the system expanded rapidly. Engineers requested additional data sources, more advanced analysis capabilities, and support for workflows beyond debug, all within the same unified context. The system evolved incrementally, incorporating these capabilities into the existing environment rather than introducing separate tools or workflows.
This expansion marked a transition from a focused debug capability to a broader platform. What began as a solution to reduce debug friction became a foundation for multiple engineering workflows operating within a shared interaction model. This shift was not planned but it emerged from sustained user demand and continuous iteration. By this stage, the core pattern was established: integrate AI directly into the workflow, unify access to engineering context, and allow capabilities to accumulate over time.
Foundation for scale: specification access
Making AI useful in silicon engineering came down to a simple constraint: models can only reason over what is available inside the working environment. Since engineers operate inside VS Code, every relevant data source had to be accessible within that context. Logs, specifications, design code, and ADO data all needed to be available without context switching.
Specification access became the forcing function for solving this problem. Earlier iterations showed that log analysis alone was insufficient. The system could summarize failures, but it could not explain them without understanding design intent. That intent lived in specifications, and without reliable access to those documents, the model’s reasoning remained incomplete.
In Windows, enterprise search could locate documents but could not reliably surface the exact clauses or relationships needed for engineering reasoning. Engineers still had to manually find and validate the relevant sections. In Linux, specification systems were not accessible within the normal workflow, making it impossible to keep design intent in the same loop as debug data. In both cases, engineers were still reconstructing context manually.
The solution was to make specification access part of the reasoning loop itself by giving the model direct access to each document. Documents were indexed into an Azure search service, and each specification was exposed as its own model context protocol (MCP) search tool. This created a one-to-one mapping between documents and tools, allowing the model to query any document explicitly instead of searching across a shared index.
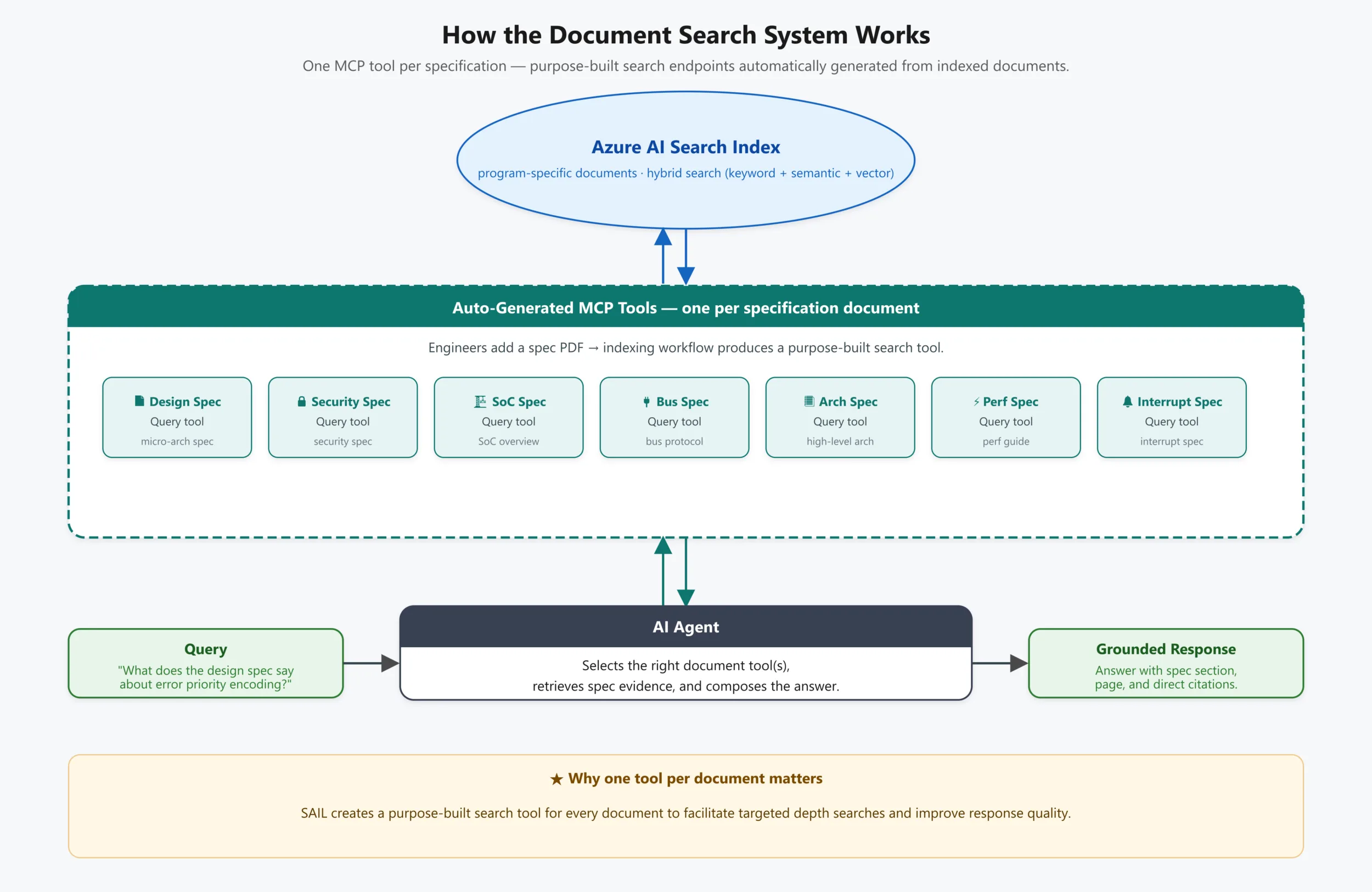
This addressed a limitation of traditional retrieval systems. Most systems return a small set of top results, filtering out lower-ranking content. In silicon workflows, those lower-signal details often contain critical constraints and edge conditions. Losing them at retrieval time limits both recall and reasoning quality.
By mapping each document to its own tool, the system avoided this loss entirely. The model could query documents independently, retain full access to each document’s content, and combine results during reasoning instead of during retrieval. This preserved detail and gave the model control over how context was assembled.
This structure enabled a different query pattern. Instead of issuing a single query and working from a compressed result set, the model could scan across documents, identify where relevant signal existed, and follow with deeper, targeted queries. This mirrors how engineers approach complex problems, moving across sources to build understanding.
The practical impact was immediate. The model was no longer limited to summarizing isolated inputs. It could retrieve precise specification clauses, connect them to design code, correlate them with ADO history, and reason across all of these sources within a single interaction. Answer quality improved because the model had access to the same level of detail an engineer would use, without losing information during retrieval.
At the time, this was viewed as a targeted solution to improve debug accuracy. Its broader significance became clear later. By enabling precise access to specification data within the same context as logs and code, this approach established the foundation for structured, multi-source reasoning. That capability became the basis for everything that followed.
From tool to community-driven platform
Once the system proved its value in debug, expansion did not follow a predefined roadmap. It was driven directly by user behavior. Engineers who had integrated the system into their debug workflows began to explore how the same interaction model could be applied to adjacent problems. This curiosity led to a natural expansion beyond debug into areas such as coverage closure, checklist validation, and broader verification workflows. The key pattern remained consistent: users were not asking for new tools, they were asking for more capability within the same context.
As usage expanded, development shifted from a single-builder model to a contribution model. Engineers began contributing enhancements back into the system, extending it to support new workflows and use cases. What started as a tightly controlled environment with a small pioneering group evolved into a community-driven development model. Contributions were no longer isolated to a single team. Instead, they reflected a growing base of engineers who were both users and builders. This transition marked a significant change in how the system evolved, with development increasingly shaped by those directly using it in day-to-day work.
To support this shift, the barrier to contribution was kept low. Engineers were encouraged to experiment and add capabilities without formal review processes, with a single constraint: contributions could not break existing functionality. This high-acceptance model encouraged experimentation and enabled rapid exploration of new workflows.
As contributions increased, the system needed a way to determine which capabilities should persist. This was addressed through usage-based selection. Contributions were tracked through telemetry and evaluated based on adoption, frequency of use, and relevance across IPs. Usage became the signal for importance, reinforcing a broader principle: prioritize usage over completeness. Widely adopted capabilities received continued investment, while others phased out over time. This allowed the system to converge on high-value functionality without heavy governance.
Distribution enabled this model to scale. The system was deployed as a co-module within design workspaces, integrating directly into environments engineers already used. Contributions propagated across all deployments, allowing improvements made in one context to benefit others immediately. This created strong leverage, where value compounded across teams without separate rollout efforts.
As a result, adoption scaled organically. The system extended beyond the initial group into broader usage across the Cobalt SoC program and was subsequently adopted by the Maia program, supporting over 200 weekly active engineers across more than 90 IPs. To date, more than 25 silicon engineers have contributed tools and workflows that benefit the Cobalt and Maia teams. This growth was not driven by top-down rollout, but by demonstrated value, peer-driven sharing, and the compounding effect of shared contributions.
By this stage, SAIL had transitioned from a tool used by a small group into a shared engineering capability. Its evolution was driven by engineers using it in their day-to-day workflows, with new capabilities emerging directly from real usage across programs.
Platform evolution
As the system expanded through sustained usage and contribution, it was no longer meaningful to describe it as a debug tool. What began as a narrowly scoped capability evolved into SAIL, spanning architecture, design, verification, and firmware workflows, and expanding from interactive assistance to more autonomous execution patterns. This transition was not planned, but emerged from the accumulation of capabilities within a consistent interaction model.
As capabilities accumulated, tools were no longer used in isolation. They were composed into multi-step workflows with a fixed objective but no predefined execution path. The system could sequence actions, evaluate intermediate results, and determine the next step dynamically, allowing it to support more complex, multi-step reasoning tasks.
This shift extended beyond assisting individual steps to structuring how problems were solved. Instead of relying on a single linear approach, the system could explore multiple hypotheses, gather evidence, and refine its reasoning based on intermediate results. This aligned naturally with silicon workflows, where failures are indirect, observability is limited, and engineers make progress by iterating on competing explanations.
A concrete example of this evolution is the SpecReviewer workflow. Enabled by the document-level indexing model described earlier, the system can reason directly over specification content. Instead of treating review as a static task, it instantiates multiple agents with distinct roles. One set proposes issues within a specification, while another independently challenges those findings using separate context and reasoning paths. Conclusions must hold up under this cross-examination before they are accepted.
In practice, this produces actionable results. Over half of the issues identified through this process result in specification updates or additional verification tests. Typical findings include ambiguous or underspecified behaviors, inconsistencies across related sections, and missing edge-case coverage. The output is a structured artifact that not only identifies issues, but explains why they matter and what actions are required.
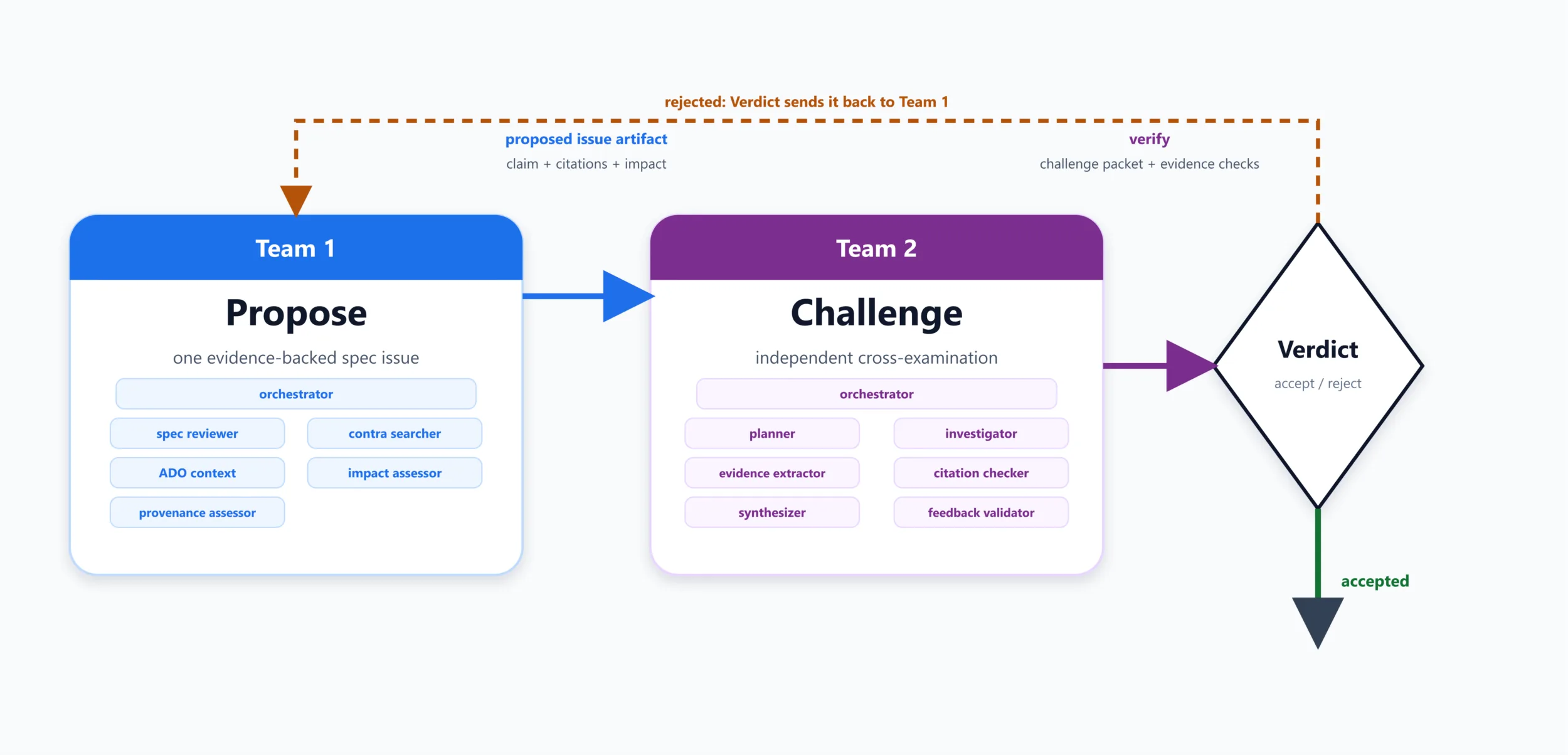
This illustrates a broader shift in the system’s role. What began as a tool for accessing and analyzing data evolved into a system that structures and validates engineering reasoning, applying the same patterns used in debug to upstream design and verification workflows.
The impact described earlier reflects this evolution. Capabilities such as improving specification quality, reducing downstream debug effort, and accelerating onboarding were not part of the initial system. They emerged as workflows became more structured and the platform accumulated more advanced reasoning capabilities.
Transferable lessons
This work reflects a broader shift in how AI can be applied in silicon engineering while demonstrating development principles that are broadly transferable. The initial effort was narrowly scoped to debug, but it revealed a more general pattern: meaningful impact does not come from applying AI to isolated tasks. It comes from embedding AI directly into the workflow and enabling it to operate over the complete engineering working context.
1. Solve the context problem first
The primary barrier to applying AI in silicon workflows is fragmented context. Systems must be designed to assemble and reason over data across specifications, logs, regressions, waveforms, and debug history. Without this, AI remains disconnected from real work.
2. Integrate into existing workflows, not adjacent tools
Adoption and impact depend on placing AI directly inside the engineer’s working environment. Systems that require context switching or parallel interaction models fail to align with how work is performed.
3. Treat workflows, not tasks, as the unit of automation
Isolated automation of individual tasks yields limited return. The greatest leverage comes from supporting multi-step reasoning within a single execution flow, where intermediate context and decisions are preserved.
4. Enable reuse through shared context and workflows
Capturing data alone is insufficient. Systems must also capture how work is done: the reasoning, decisions, and patterns used by engineers. When these workflows are reusable, value compounds as contributions propagate across teams.
5. Favor rapid, usage-driven iteration over traditional development cycles
AI capabilities evolve faster than conventional software processes can accommodate. Effective systems are built through continuous iteration based on real usage, with tight feedback loops and low friction for adding new capabilities.
6. Maintain a single, coherent working context
Fragmentation across tools and environments introduces overhead and loss of fidelity. Systems that preserve a unified context enable both humans and AI to reason more effectively and reduce the need for manual reconstruction.
Taken together, these principles reinforce a common theme: AI systems are most effective when they are embedded into real workflows, operate over complete context, and evolve through continuous use.
Post Updated on June 1, 2026 at 04:07PM
Thanks for reading
from devamazonaws.blogspot.com

Comments
Post a Comment